데이터 전처리
: 데이터를 분석 및 처리에 적합한 형태로 만드는 과정으로 반드시 거쳐야 하는 과정이다.
sklearn.preprocessing 패키지
: 모델을 만들기 적합한 데이터로 변환하는 것을 도와줌 -> x값
1. 결측치 추정 : Null 비율 20% 미만
2. 레이블 인코딩 : 문자를 숫자로 변환
3. 표준화 : 최대값 및 최소값 정의
4. 구간화 : 연속형(이상치 제외 평균)에서 범주형(Null 값을 미리 정의된 값으로 대체)으로 변형
# 정규화, 표준화
import seaborn as sns
iris = sns.load_dataset('iris')
x = iris.iloc[:, :-1]
y = iris.iloc[:, -1]# 표준화(standardization) : 연속형 데이터의 경우 변수들의 Scale이 다르면 모델링 과정이 제대로 수행이 안되기 때문에 표준화를 시킨다.
# 데이터 전처리 : scaling
from sklearn.preprocessing import scale
x_scale = scale(x)
x_scale[:5, :]# scale(x) : 표준 정규분포를 사용해 표준화 → 평균 : 0, 표준편차 : 1

x_scale.mean(axis=0)
# axis = 0 : 서로 다른 행끼리 / axis = 1 : 서로 다른 열끼리 / default(기본값) : axis = 0
from sklearn.preprocessing import minmax_scale
sc = minmax_scale(x)
sc[:5, :]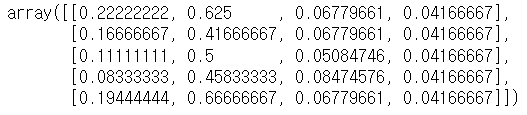
# 0 ~ 1 사이 값으로 스케일링(단위 조정)
# minmax_scale() : 최대값과 최솟값을 사용하여 표준화
from sklearn.preprocessing import StandardScaler
sc = StandardScaler() # 평균 : 0, 표준편차 : 1
sc.fit(x)
# fit() : 스케일링에 사용될 평균과 표준편차를 계산
fit() : 데이터에 머신러닝 모델을 맞추도록 훈련시키는 함수(데이터셋에서 변환을 위한 기반 설정)
transform() : fit() 통해 세운 기반으로 실제 학습시킨 것을 적용
iris_scale = sc.transform(x)
iris_scale[:5, :]
# transform(): 표준화를 수행해서 데이터 변환
sc.inverse_transform(iris_scale)[:5, :]# 데이터(iris_scale)를 원래 표현으로 스케일 백 함
y# y의 결과 값의 데이터 형태인 문자는 빈도수만 알 수 있다.

위에 언급한 것처럼 문자는 빈도수만 알 수 있기 때문에 여기서 레이블 인코딩(Label Encoding)이 필요하다.
레이블 인코딩
: 실제 값에 상관없이 0 ~ k-1 까지의 정수로 변환하는 것
(예) 지역 또는 성별 등 문자로 되어있는 데이터를 숫자로 변환한다.
from sklearn.preprocessing import LabelEncoding
le = LabelEncoder()
le.fit(y) #레이블 인코더 모델 생성
species = le.transform(y) #라벨을 표준화된 인코딩으로 변환
species
One-Hot Encoding
: 클래스의 수만큼 0 또는 1을 갖는 열을 이용해서 데이터 표현
(예) 성별을 저장하는 변수가 male, female을 가진다면 새로운 두 개의 변수(A_m, B_fm)를 만들고 male일 경우 두 변수가 각각 1, 0값을 가지며, female일 경우 두 변수가 각각 0, 1값을 가짐
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(categories = 'auto')
ohe.fit(species.reshape(-1, 1))
iris_onehot = ohe.transform(species.reshape(-1, 1))
iris_onehot
# 결과 : (150, 1) → 150개의 샘플 수 , 1열
# reshape() : 데이터 수를 해당 열 개수만큼 자동 구조화
# reshape(-1, 1) : 행의 위치를 나타나는 곳에 '-1'은 열의 값은 특정 정수로 지정되어 있을 때, 남은 배열의 길이와 남은 차원으로부터 추정해서 알아서 지정하라는 뜻 (마지막 )을 의미하고, 열의 위치에 있는 '1'은 1열로 나타내라는 의미이다.
iris_onehot.toarray()[:5]
# 배열로 변환
#판다스 활용한 One Hot Encoding
import pandas pd
pd.get_dummies(iris.species)# get_dummies() : 더미변수 (예) 수영장이 있으면 1, 없으면 0
→ get_dummies()를 이용하면 간단히 원핫 인코딩괸 결과를 얻을 수 있다.

# 평균값 인코딩
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic.head()
titanic.isnull().sum() # null값 확인
# 결과를 보면 deck가 다른 칼럼들의 비해 null값이 많음 (결측치가 많음)
titanic.info()
# null값과 데이터 프레임 확인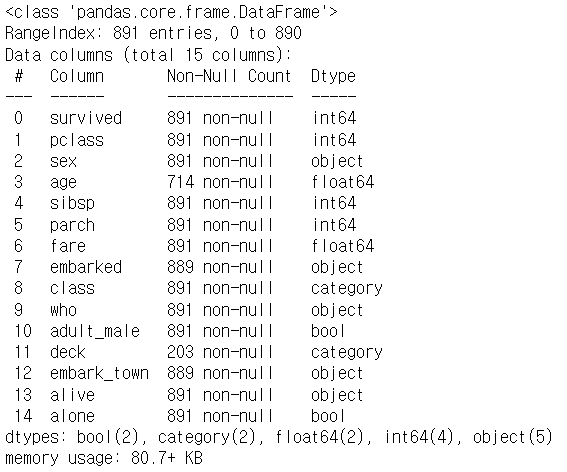
sex_mean = titanic.groupby('sex')['survived'].mean()
# titanic에 대한 것 중 'sex'를 그룹화하고 거기에 따른 'survived' 생존에 따른 평균값을 sex_mean에 저장한다.
titanic['sex_mean'] = titanic['sex'].map(sex_mean)
titanic[:5]
# titanic['sex'].map(sex_mean) : sex_mean인 평균값을 sex_mean이라는 칼럼을 생성해 추가!
# sex, sex_mean 변수 추출
titanic[['sex', 'sex_mean']].head()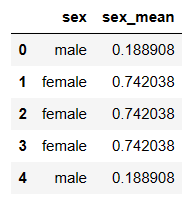
# pivot table로 정리
titanic_pivot = titanic.titanic_pivot(index = titanic.index,
columns = 'survived',
values = 'sex_mean')
titanic_pivot[:5]
# 남자 : 0.188908 / 여자 : 0.742038
# 0 : 생존 / 1 : 사망
titanic_pivot.hist(bins = 10)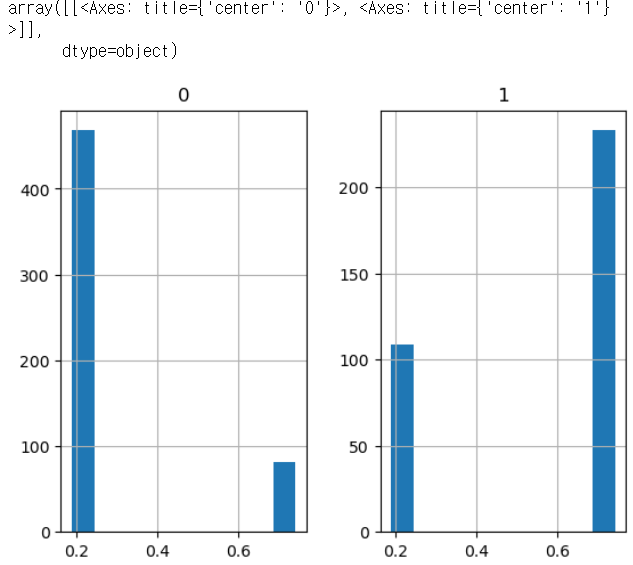
▶ 에측값을 히스토리 차트로 보면 남자(0.188908)가 여자(0.742038)보다 생존률(0)이 더 높다는 것을 알 수 있다.
▶ 평균값 인코딩의 장점은 만들어지는 특정변수의 수가 매우 적어, One-hot의 문제였던 차원의 저주가 없어 비교적 빠른 학습이 가능하다.
# nan 생성
import random
random.seed(42)
for col in range(4) :
x.iloc[[random.sample(range(len(iris)), 20], col] = flot('nan') # nan 생성
x.head()
# 랜덤으로 iris 데이터 길이 중에서 20개만 뽑은 행과 col의 열을 가져와 nan으로 추가
imputer 활용, nan(결측치) 해결(평균, 중위수로 대체)
# x에 대한 행 평균값(mean)
x.mean(axis=0)
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer(strategy = 'mean')
imp_mean.fit(x) # 학습
imp_mean.transform(x)[:5, :] #Nan 값을 평균값으로 변경# impute 모듈의 SimpleImputer 클래스를 이용하면 데이터의 평균, 중앙값, 최빈값 또는 상수값 중 하나로 결측값을 채울 수 있음
# SimpleImputer(strategy = 'mean') : 결측값을 평균값(mean)으로 채울 방법 지정

# x에 대한 행 중위값(median)
x.median(axis=0)
imp_median = SimpleImputer(strategy = 'median')
imp_median.fit(x)
imp_median.tansform(x)[:5, :]# SimpleImputer(strategy = 'mean') : 결측값을 중앙값(median)으로 채울 방법 지정

# x에 대한 행 최빈값(mode)
x.mode(axis=0)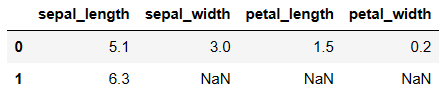
imp_freq = SimpleImputer(strategy='most_frequent')
imp_mostfreq = imp_freq.fit_tansform(x)
imp_mostfreq[:5, :]
(천안 스타형 학습 과정에서 배운 내용 복습 및 모르는 내용 서칭 후 추가 작성)
'Project > 23.07~08 AI' 카테고리의 다른 글
| 머신러닝_5. 단순회귀분석_규제 (0) | 2023.07.11 |
|---|---|
| 머신러닝_4. 모델링 (0) | 2023.07.11 |
| 머신러닝_3. 데이터 분리 (0) | 2023.07.11 |
| 머신러닝_1. 데이터 탐색 (0) | 2023.07.10 |
| 머신러닝_0. 개요 (0) | 2023.07.10 |